|
YobeSDK Android 0.3.2
|

|
|
YobeSDK Android 0.3.2
|
|
The Near-LATTE (Lock And Track Type Engine) variant for AVR-listening within the Yobe SDK performs Automatic Voice Recognition (AVR) on the voice of a pre-enrolled user to extract their voice from surrounding noise and human crosstalk to determine when the pre-enrolled user is silent and consequently mute the entire signal at those times. The software also has the capability of enrolling a user on the basis of 10-20 seconds of unscripted speech. The Voice Template is used to determine the intervals that a pre-enrolled user is not talking. During those intervals, the audio signal is muted. Typical use cases for the Near-LATTE variant for AVR-listening is a registered user engaged in a two way conversation and needing the signal to be entirely muted when they are not speaking or a solution wanting to input or record only the authorized speaker at all times, even though there may be other people speaking as well as other sources of noise.
The Near-LATTE variant for AVR-listening has the following capabilities:
Note: Only one user can be enrolled at a time.
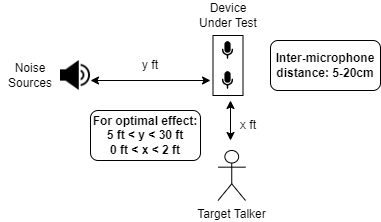

This Yobe Android SDK package contains the following elements:
speech.aar library that provides the Yobe Android SDKPlace the provided .aar in the proper location for implementing in your android project. It is common to include the library in your project in the dependencies of the build.gradle.
See the Android Studio Documentation on adding build dependencies for more details.
The IDListenerSpeech requires permissions to use the device's microphones in order to capture audio data for processing. In your project's AndroidManifest.xml you can place this entry inside the manifest tag:
LATTE's main functionality is accessed via the com.yobe.speech.IDListener class.
Create a new com.yobe.speech.IDListener instance. The instance must then be initialized using the license provided by Yobe, as well as two configuration arguments: the Microphone Orientation and the Output Buffer Type.
A com.yobe.speech.IDTemplate must be created using the desired user's voice so the IDListener can select that template and identify the voice.
Register the user by inputting their voice audio data using com.yobe.speech.IDListener.RegisterTemplate. This is done using a continuous array of audio samples.
It is recommended to first process the audio data so that only speech is present in the audio; this will yield better identification results. To achieve this, the IDListener can be placed into Enrollment Mode. In this mode, the audio that should be used to create a BiometricTemplate is processed, buffer-by-buffer, using Yobe::IDListener::ProcessBuffer. This ProcessBuffer will return a status of com.yobe.speech.Status.ENROLLING as long as the buffers are being processed in Enrollment Mode. Enrollment Mode is started by calling com.yobe.speech.IDListener.StartEnrollment, and is stopped by either manually calling com.yobe.speech.IDListener.StopEnrollment or by processing enough buffers for it to stop automatically based on an internal counter (currently, this is enough buffers to equal 20 seconds of audio).
Enrollment Mode can be started at any point after initial calibration. Any samples processed while in Enrollment Mode will not be matched for identification to a selected template, if there is one.
Select the user using the template returned by the registration.
Any new audio buffers passed to com.yobe.speech.IDListener.ProcessBuffer will be processed with respect to the selected user's voice.
Audio data is passed into the com.yobe.speech.IDListener one buffer at a time. See Audio Buffers for more details on their format. The audio is encoded as PCM 16-bit Shorts.
result in the above example has an entry that contains the processed version of the audio that is contained in buffer. An example of what to do with this data is to append its contents to a stream or larger buffer.
Note: You can find the library's built in buffer size using com.yobe.speech.Util.GetBufferSizeSamples.
To ensure proper clean up of the IDListener, simply call com.yobe.speech.IDListener.Deinit.
LATTE's real-time functionality is accessed via the com.yobe.speech.IDListenerSpeech class.
Then, in your project, you must either prompt the user for relevant permission or enable the permission in the app's settings on the device.
An IDListenerSpeech object can be created using a class that implements com.yobe.speech.AudioConsumer.
see Define Real-Time Processing Callbacks for details on MyAudioConsumer
Creating a com.yobe.speech.IDListenerSpeech object requires an object that implements the callback functions in the com.yobe.speech.AudioConsumer interface. These callback functions will receive processed audio buffers for further processing in real-time. Audio data is captured by the device's microphones, processed, and sent to the com.yobe.speech.AudioConsumer.onDataFeed callback function one buffer at a time. See Audio Buffers for more details on audio buffers. The status after each processing step is sent via a call to the com.yobe.speech.AudioConsumer.onResponse callback function.
The output buffers are arrays of short values.
Note: The originalBuffer will contain two channels of interleaved audio data, while the processedBuffer will only contain one channel of audio data.
The processedBuffer callback argument in onDataFeed can be thought of as the output of the com.yobe.speech.IDListener.ProcessBuffer function. Further processing or storage can be done. However, it's important to minimize runtime spent in the callback function to keep the audio processing running at real-time speeds.
The functions for performing IDTemplate registration and selection are the same as the IDListener, in the section Register and Select User. For live, processed enrollment, simply implement Option 2 in the onDataFeed callback.
Processing is started via com.yobe.speech.IDListenerSpeech.Start and stopped via com.yobe.speech.IDListenerSpeech.Stop. Once started, the callback functions will start being called with the processed audio buffers in real-time.
Note: A IDListenerSpeech object has a startup time of 5 seconds upon calling Start. The IDListenerSpeech object status will prompt for more data by reporting the com.yobe.speech.SpeechUtil.Status.NEEDS_MORE_DATA code in onResponse until this startup time has passed. After the startup time has passed, the onResponse will report com.yobe.speech.SpeechUtil.Status.OK.
To stop and clean up the IDListenerSpeech object, simply call com.yobe.speech.IDListenerSpeech.Stop.