|
YobeSDK Android 0.2.3
|

|
|
YobeSDK Android 0.2.3
|
|
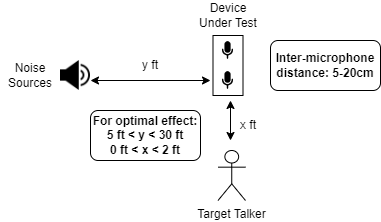
The Near-CAFE (Conversational Audio Front-End) variant within the Yobe SDK is meant for situations where a person is talking close to a device while there are noise sources (including other voices) much farther from the device. The job of Near-CAFE is to extract the voice of the near-field person while pushing the far-field noise sources further into the auditory background. A typical use case would be a person talking into a smartphone while there is considerable ambient noise in the environment.

This Yobe Android SDK package contains the following elements:
speech.aar library that provides the Yobe Android SDKPlace the provided .aar in the proper location for implementing in your android project. It is common to include the library in your project in the dependencies of the build.gradle.
See the Android Studio Documentation on adding build dependencies for more details.
The BioListenerSpeech requires permissions to use the device's microphones in order to capture audio data for processing. In your project's AndroidManifest.xml you can place this entry inside the manifest tag:
CAFE's real-time functionality is accessed via the com.yobe.speech.BioListenerSpeech class.
Then, in your project, you must either prompt the user for relevant permission or enable the permission in the app's settings on the device.
A BioListenerSpeech object can be created using a class that implements com.yobe.speech.AudioConsumer.
Creating a com.yobe.speech.BioListenerSpeech object requires an object that implements the callback functions in the com.yobe.speech.AudioConsumer interface. These callback functions will receive processed audio buffers for further processing in real-time. Audio data is captured by the device's microphones, processed, and sent to the com.yobe.speech.AudioConsumer.onDataFeed callback function one buffer at a time. See Audio Buffers for more details on audio buffers. The status after each processing step is sent via a call to the com.yobe.speech.AudioConsumer.onResponse callback function.
The output buffers are arrays of short values. The output buffer size can also vary from call to call.
Note: The originalBuffer will contain two channels of interleaved audio data, while the processedBuffer will only contain one channel of audio data.
Processing is started via com.yobe.speech.BioListenerSpeech.Start and stopped via com.yobe.speech.BioListenerSpeech.Stop. Once started, the callback functions will start being called with the processed audio buffers in real-time.
Note: A BioListenerSpeech object has a startup time of 5 seconds upon calling Start for the first time. The BioListenerSpeech object status will prompt for more data by reporting the com.yobe.speech.SpeechUtil.Status.NEEDS_MORE_DATA code in onResponse until this startup time has passed. After the startup time has passed, the onResponse will report com.yobe.speech.SpeechUtil.Status.OK.
To stop and clean up the BioListenerSpeech object, simply call com.yobe.speech.BioListenerSpeech.Stop.