|
YobeSDK 0.3.2
|

|
|
YobeSDK 0.3.2
|
|
These sections provide explanations and details on important terms used by the Yobe library.
Audio buffers are arrays that contain audio sample data. They are a fixed size and are passed into the Yobe processing functions which outputs processed versions of the buffers. The audio buffer data must be interleaved as well and must be either 16-bit PCM or double encoded. The data is interleaved by pairing the samples from mic 1 followed by mic 2 in order. The buffer sizes can be 128ms, 256ms, 512ms, or 1024ms long at 16kHz, however this size is built into the library and can be verified using Yobe::Info::InputBufferSize.
Automatic Speech Recognition is a process through which audio can be transcribed into text to perform a specific function. The Yobe library output works well with various ASR engines by providing them with noise free audio data.
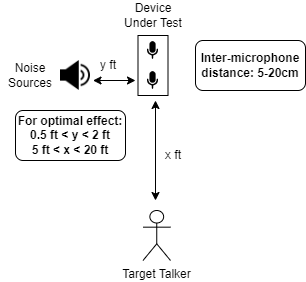
This is the audio capture scenario where the target voice is at a relatively farther distance from the device under test, as compared to the noise to be suppressed. An example scenario would be a person talking to an appliance (that is making its own noise) from afar.
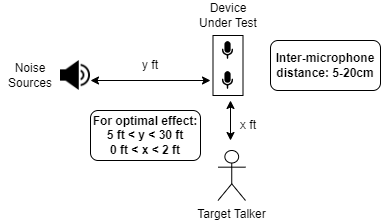
This is the audio capture scenario where the target voice is at a relatively closer distance from the device under test, as compared to the noise to be suppressed. A typical use case would be a person talking into a smartphone while there is considerable ambient noise in the environment.
The voice template is an audio template related to a specific user that can be used as a reference to be able to identify said user.
The Yobe SDK makes a distinction between two different microphone configurations: end-fire and broadside. These names correspond with physical placement of the microphones relating to the direction of the incoming speech (not the noise).
This configuration positions the mics so that the segment created by the mics is orthogonal to the direction that the speaker is talking from. This results in the voice reaching both microphones at approximately the same time.

This configuration positions the mics so that the segment created by the mics is coincident with the direction vector that the speaker is talking from. This results in the sound reaching each microphone with a non-negligible time difference, and mimics a common scenario for hand-held devices, like phones, where one mic is on the bottom and the other is on the top.

This value determines the size of an output buffer returned by the Yobe ProcessBuffer function in the LATTE variant. The output buffer can be of type FIXED or VARIABLE.
This type is recommended for most applications. The size of the output buffer will always be the same. This is idea for real-time scenarios where the processed audio is part of a chain of processing that is designed to output in real-time. An example application is an automatic muting functionality.
THis type is more suited for applications where delay is tolerable and expected. The size of the output buffer may change, and must be evaluated at each ProcessBuffer call. An example application is one that sends processed audio to a cloud-based Automatic Speech Recognition (ASR) engine.